Introduction
⚠️ Warning: These docs are in the process of being updated - the latest significant revision was September 2024. Neuronpedia has expanded beyond SAE-specific research to include probes, "concepts", transcoders, and more. Additionally, Neuronpedia has many more functionalities than documented here.

What is Neuronpedia?
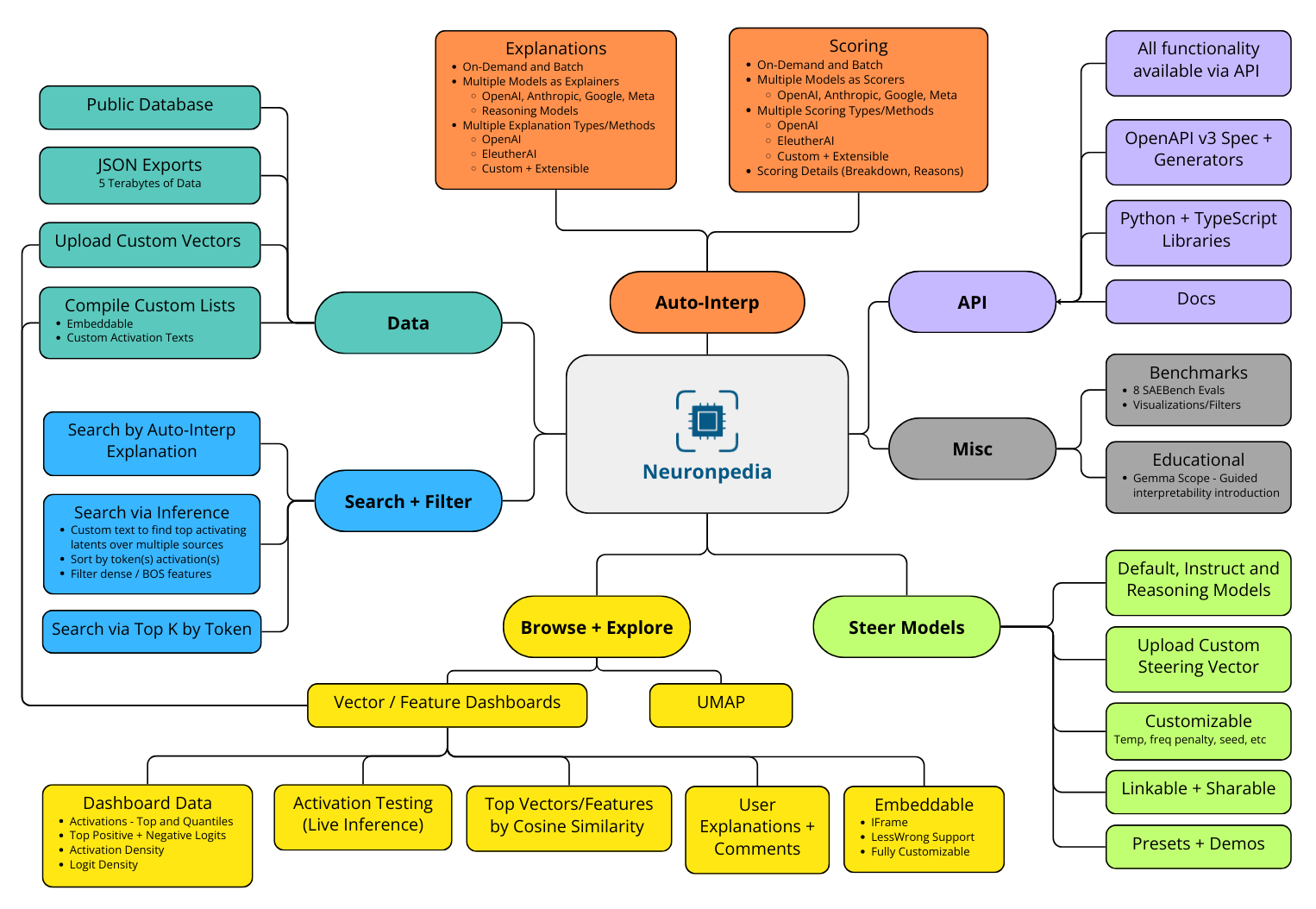
Neuronpedia is an open platform for mechanistic interpretability research. It's both a public database of useful data for researchers (including activations, explanations, and metadata, and more), as well as a suite of free APIs/tools that accelerate white-box understanding and experimentation of neural networks.
These docs explain Neuronpedia's features and how to use them. Please email us if you have further questions or comments. We love feedback!
Why Neuronpedia?
TL;DR - Researchers do research. We accelerate them by doing everything else: visualizations, tooling, sharing/collaboration, scaling, and hosting.
Research Focus
Neuronpedia was previously focused specifically on SAE (Sparse Autoencoder) research. However, the infrastructure is now generalized to support all mech interp research, including but not limited to probes, "concepts", transcoders, and more.
Demo Tweets (Short)
Here's our launch tweet thread with GIFs showcasing Neuronpedia. It's a bit outdated now, but it's still a fun and relevant demo:
For even more detail and background, check out our launch post on LessWrong.